偷懒是人类进步的阶梯
前言
先上图
![内容提取]()
左边是 PDF 文档,右边是表单,需要从左边的文档中提取相关信息填入右边相应的文本框。
至于 PDF 的处理,下次再讲。本文专注于使用 Selenium 控制 Chrome 来填写相关字段。
单选框
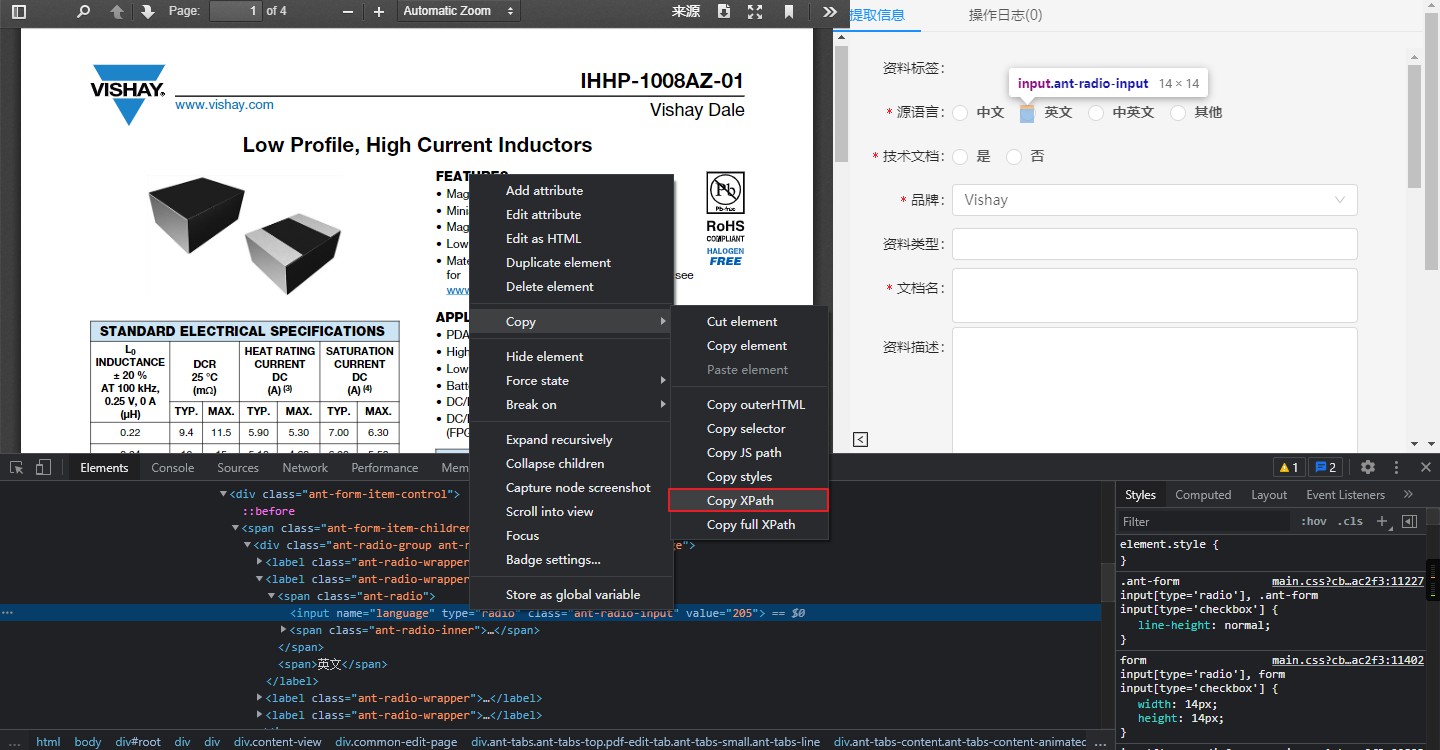
首先是源语言和技术文档,以英文语言为例,在 Chrome 里,鼠标停留在“英文”前的按钮,使用“检查元素”功能,在下方的调试窗口,右键“Copy->Copy XPath”(如下图),得到“英文”对应的 XPath,使用 Selenium 提供的click()函数实现点击,代码如下。
![XPath]()
1
2
3
4
5
6
7
| from selenium import webdriver
driver = webdriver.Chrome(options=options)
driver.maximize_window()
driver.get(link)
driver.find_element_by_xpath('//*[@id="language"]/label[2]/span[1]/input').click()
driver.find_element_by_xpath('//*[@id="techFlag"]/label[1]/span[1]/input').click()
|
文本框
然后是各个文本框,可以使用find_element_by_id方法定位。以“文档名”为例,使用“检查元素”功能,可以看到其id是fileName,在提取资料的文档名后(假设为file_name),使用send_keys()函数填写内容,代码如下:
1
2
|
driver.find_element_by_id('fileName').send_keys(file_name)
|
send_keys(str)的参数可以是带有转义字符的字符串,以’\n’为例,填入到文本框后能实现换行。
按钮
填写完所有必填文本框后,来到页面底部的“下一步”按钮,这里可以使用 XPath(很长,显得代码不够优雅)定位;由于页面上只有一个button,所以可以直接用 CSS 选择器定位button,或者使用类名定位,代码如下:
1
2
| driver.find_element_by_class_name('ant-btn').click()
driver.find_element_by_css_selector("button").click()
|
然后弹出一个对话框会提示提交成功,需要再点一次“确定”按钮,这里按 XPath 选择,代码如下:
1
| driver.find_element_by_xpath('/html/body/div[3]/div/div[2]/div/div[2]/div/div/div[2]/button').click()
|
部分代码
部分代码如下,其中,由于程序顺序执行相邻指令的时间间隔很短,如果不设置time.sleep(),那么在执行下一条指令前,页面上并没有出现相应的元素,将导致程序报错。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
driver.find_element_by_xpath('//*[@id="language"]/label[2]/span[1]/input').click()
driver.find_element_by_xpath('//*[@id="techFlag"]/label[1]/span[1]/input').click()
driver.find_element_by_id('fileType').send_keys('Datasheet')
driver.find_element_by_id('fileName').send_keys(file_name)
driver.find_element_by_id('docDesc').send_keys(desc)
driver.find_element_by_id('pnTags_Temporary').send_keys(models)
driver.find_element_by_id('fileCategory').send_keys(category)
driver.find_element_by_id('fileApplication').send_keys(apps)
driver.find_element_by_id('filePackage').send_keys(package)
driver.find_element_by_id('fileCreateTime').send_keys(create_time)
driver.find_element_by_id('fileCode').send_keys(file_code)
driver.find_element_by_id('fileVersion').send_keys(file_verion)
driver.find_element_by_css_selector("button").click()
time.sleep(3)
driver.find_element_by_xpath('/html/body/div[3]/div/div[2]/div/div[2]/div/div/div[2]/button').click()
while True:
try:
driver.find_element_by_xpath('//*[@id="linkCheckStatus"]/label[1]/span[1]').click()
break
except NoSuchElementException:
pass
time.sleep(3)
driver.find_element_by_css_selector("button").click()
time.sleep(3)
driver.find_element_by_xpath('/html/body/div[3]/div/div[2]/div/div[2]/div/div/div[2]/button').click()
|
Chrome 浏览器选项
默认情况下,Selenium 会以窗口化运行 Chrome,下载路径是默认的~/Downloads目录,可以使用以下代码修改配置。
1
2
3
4
5
6
7
8
9
|
options = webdriver.ChromeOptions()
prefs = {
'profile.default_content_settings.popups': 0,
'download.default_directory': 'C:\\Users\\username\\Downloads\\PDF'
}
options.add_experimental_option('prefs', prefs)
driver = webdriver.Chrome(options=options)
driver.maximize_window()
|
代码调试
为了方便查看每一步的运行效果,可以使用 Jupyter Notebook。实测 IPython 在打开 Chrome 后会停在当前输入,不能输入新命令,所以 IPython 并不能用于单步。